
“Model tốt nhất không phải model to nhất — mà là model vừa khít GPU của bạn như đôi giày vừa chân.”
Tại Sao Nên Chạy AI Trên Máy Cá Nhân? 🏠
AI trên cloud thì tiện — cho đến khi bạn nhận ra:
- 💸 Phí subscription chồng chất — $20/tháng chỗ này, $30/tháng chỗ kia
- 🔒 Lo ngại bảo mật — dữ liệu của bạn gửi lên server người khác
- 🌐 Phụ thuộc internet — mất WiFi là mất AI
- 🐌 Giới hạn sử dụng — “Bạn đã hết lượt, thử lại sau 2 giờ”
Chạy AI trên máy cá nhân nghĩa là dữ liệu của bạn ở yên trên máy, free mãi mãi, và chạy offline được. Chi phí duy nhất? phần cứng — và biết chọn model nào.
Đó là lý do LM Studio ra đời. Nó là cách dễ nhất để tải, chạy và quản lý LLM trên PC của bạn.
Quy Tắc Vàng: VRAM Là Vua 👑
Trước khi đi sâu vào cách đọc thông số model, hãy hiểu một sự thật:
VRAM của GPU quyết định bạn chạy được model gì.
Không phải CPU. Không phải RAM (phần lớn). Mà là VRAM.
Lý do: LLM cần load hàng tỷ tham số vào bộ nhớ để sinh text. Khi tất cả tham số nằm gọn trong VRAM, bạn sẽ có tốc độ xử lý cực nhanh (20–40+ token/s). Khi không đủ, model sẽ tràn sang RAM hệ thống và chạy bằng CPU — chậm hơn 10–50 lần.
| VRAM | Chạy Được Model Gì |
|---|---|
| 4 GB | Chỉ 1B–3B (rất cơ bản) |
| 6 GB | 3B–7B ở quantization Q4 |
| 8 GB | 7B ở quantization Q4–Q5 |
| 12 GB | 7B–14B (điểm ngọt!) |
| 16 GB | 14B–22B |
| 24 GB | 22B–34B, hoặc 70B ở Q2 |
Hiểu Về Tham Số Model 🧠
Khi bạn thấy “7B” hoặc “14B” trong tên model, đó là số tham số (tính bằng tỷ). Coi như “kích thước não” của model:
| Tham Số | Mức Độ Thông Minh | Model Ví Dụ |
|---|---|---|
| 1B–3B | Trợ lý cơ bản, hỏi đáp đơn giản | Qwen2.5-1.5B, Phi-3-mini |
| 7B–9B | Đa năng tốt, hỗ trợ code ổn | Llama 3.1 8B, Qwen3.5 9B, Mistral 7B |
| 14B | Thông minh, giỏi suy luận & code | Qwen2.5-14B, DeepSeek-R1-Distill-14B |
| 32B–34B | Rất giỏi, gần bằng cloud | Qwen2.5-32B, CodeLlama-34B |
| 70B+ | Đỉnh cao trí tuệ, cần phần cứng khủng | Llama 3.1 70B, Qwen2.5-72B |
Cái bẫy: Não to hơn = cần nhiều VRAM hơn. Model 70B cần ~40+ GB VRAM ở Q4. Trừ khi bạn có RTX 4090 hoặc dual GPU, hãy chọn model vừa GPU.
Quantization: Nghệ Thuật Nén 🗜️
Đây là phép thuật giúp bạn chạy model khổng lồ trên phần cứng phổ thông: quantization (lượng tử hóa).
Quantization giảm độ chính xác của mỗi tham số từ 16-bit (FP16) xuống các định dạng bit thấp hơn, thu nhỏ model mà vẫn giữ phần lớn trí thông minh.
| Quantization | Chất Lượng | Giảm Kích Thước | Khi Nào Dùng |
|---|---|---|---|
| FP16 | ★★★★★ Gốc | 1× (baseline) | Chỉ khi có thừa VRAM |
| Q8_0 | ★★★★★ Gần hoàn hảo | ~0.5× | Model vừa khít FP16 |
| Q6_K | ★★★★☆ Xuất sắc | ~0.4× | Tỷ lệ chất lượng/kích thước tốt nhất |
| Q5_K_M | ★★★★ Rất tốt | ~0.35× | Cân bằng tốt |
| Q4_K_M | ★★★☆ Tốt | ~0.3× | Phổ biến nhất — đáng đồng tiền bát gạo |
| Q3_K_M | ★★☆ Chấp nhận được | ~0.25× | Ép model to hơn vào |
| Q2_K | ★☆ Giảm chất lượng rõ | ~0.2× | Phương án cuối, chất lượng tệ |
| IQ4_XS | ★★★ Tốt (imatrix) | ~0.28× | Quantization nâng cao, nhỉnh hơn Q3 |
Quy Tắc Nhanh
Kích thước file model ≈ VRAM cần thiết
File 6.55 GB cần khoảng 6.55 GB VRAM, cộng thêm ~1–2 GB cho context.
Nếu bạn có 12 GB VRAM, hãy chọn file model ≤ 10 GB để còn chừa chỗ cho context và hệ thống.
Cách Đọc Trang Model Trên LM Studio 📖
Hãy cùng phân tích một ví dụ thực tế từ LM Studio. Đây là những gì bạn thấy khi click vào một model:
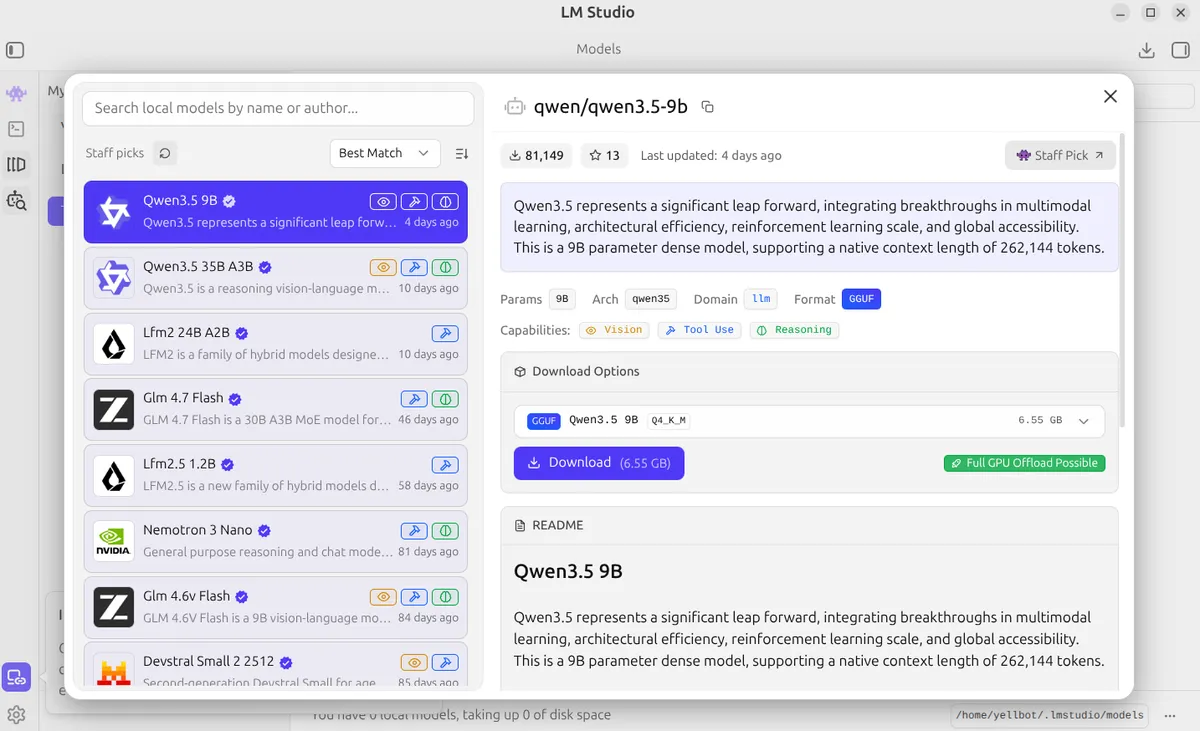
Ví Dụ Thực Tế: Model Này Có Hợp Với PC Của Tôi Không?
Lấy một cấu hình PC thực tế làm ví dụ để phân tích xem model Qwen3.5 9B Q4_K_M (6.55 GB) có phù hợp không:
| Linh Kiện | Thông Số |
|---|---|
| CPU | Intel Core i5-14400F (16 luồng) |
| RAM | 32 GB DDR |
| GPU | NVIDIA RTX 4070 (12 GB VRAM) |
Phân Tích:
- ✅ Kiểm tra VRAM: Model 6.55 GB < 12 GB VRAM — hoàn toàn vừa vặn, còn dư 5.45 GB cho context
- ✅ Full GPU Offload: Có — toàn bộ layer được load thẳng vào GPU, không rơi về CPU
- ✅ Chỗ trống Context: Đủ VRAM dư để chạy thoải mái context length từ 8192+
- ✅ Tốc độ dự kiến: 30–40+ tok/s trên RTX 4070 — cảm giác gần như tức thì
- 🔥 Có thể chơi lớn hơn: Với 12 GB VRAM, một model 14B Q4_K_M (~9 GB) vẫn có thể offload toàn bộ lên GPU
Kết luận: Qwen3.5 9B Q4_K_M là một sự kết hợp hoàn hảo cho cấu hình này — nhanh, thông minh, và còn dư dả khoảng trống để tăng context length. Bạn thậm chí có thể thử các model 14B để có độ thông minh cao hơn.
Bây giờ hãy cùng phân tích từng phần trên trang giao diện này:
Thanh Thống Kê Phía Trên
| Chỉ Số | Ý Nghĩa |
|---|---|
| ⬇️ Lượt tải (vd: 81,149) | Độ phổ biến — càng cao càng đáng tin |
| ⭐ Stars (vd: 13) | Cộng đồng yêu thích |
| 🕐 Cập nhật lần cuối | Model mới thường được tối ưu tốt hơn |
| 🏷️ Featured / Staff Pick | Được team LM Studio tuyển chọn — tín hiệu chất lượng cao |
Thẻ Metadata Model
| Thẻ | Cho Bạn Biết Gì |
|---|---|
Params (vd: 9B) | Kích thước não — to hơn = thông minh hơn nhưng cần nhiều VRAM |
Arch (vd: qwen35) | Họ kiến trúc (Qwen, Llama, Mistral, v.v.) |
Domain (vd: llm) | Loại model — llm cho text, vlm cho vision+language |
Format GGUF | ✅ Đây là format bạn cần! GGUF được tối ưu cho chạy local |
Badge Khả Năng
Các badge màu cho bạn biết model làm được gì ngoài chat cơ bản:
| Badge | Ý Nghĩa | Trường Hợp Sử Dụng |
|---|---|---|
| 👁️ Vision | Hiểu được hình ảnh | Mô tả ảnh, đọc screenshot, phân tích sơ đồ |
| 🔧 Tool Use | Gọi được function và tool bên ngoài | Tích hợp API, output có cấu trúc |
| 🧠 Reasoning | Tư duy từng bước nâng cao | Toán, logic, code, phân tích phức tạp |
Tùy Chọn Tải — ⚠️ PHẦN QUAN TRỌNG NHẤT
Đây là nơi quyết định thực sự xảy ra:
| |
Thấy 👍 nút like bên cạnh một quantization chưa? Đó là đề xuất “An Toàn & Cân Bằng” của LM Studio. Nó gợi ý phiên bản chừa lại nhiều khoảng trống VRAM nhất cho hệ điều hành và context length lớn. Nút Like chọn giải pháp an toàn.
Nhưng nếu bạn muốn đẩy phần cứng đến giới hạn thì sao? Đó là lúc cần nhìn vào Tên Lửa Xanh.
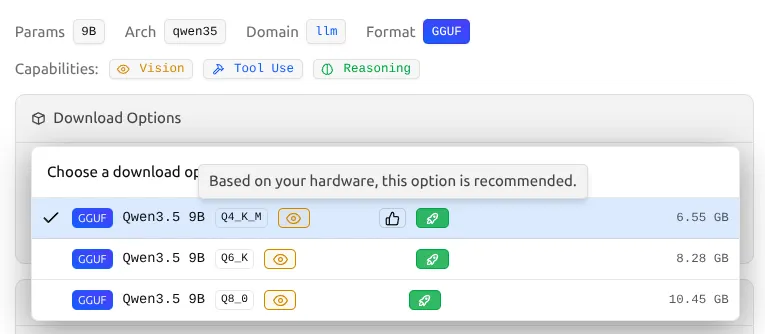
Giải mã:
- GGUF — Định dạng file (đã quantize, sẵn sàng chạy local)
- Q4_K_M — Mức quantization (xem bảng ở trên)
- 6.55 GB — Xấp xỉ VRAM bạn cần
🚀 Badge Tên Lửa Xanh: “Full GPU Offload Possible”
Đây là chỉ số quan trọng nhất cho trải nghiệm của bạn:
Khi chọn một mức quantization, hãy nhìn kỹ vào cái badge màu xanh hiện ra bên cạnh.
| Badge | Ý Nghĩa | Hành Động |
|---|---|---|
| 🟢 Badge Tên Lửa Xanh | Toàn bộ model nằm gọn trong VRAM | ✅ Tải ngay! Đảm bảo chạy nhanh |
| 🔵 Badge Xanh Dương “Partial” | Một số layer chạy bằng CPU | ⚠️ Sẽ chậm hơn rõ rệt |
| 🔴 Badge Đỏ “Likely too large” | Vượt quá bộ nhớ hệ thống | ❌ Bỏ qua — Không khuyến nghị tải |
Ví dụ, trên RTX 4070 với 12GB VRAM, model Qwen3.5 9B Q8_0 (10.45 GB) vẫn hiện tên lửa xanh. Điều này có nghĩa là đúng vậy, PC của bạn hoàn toàn có thể chạy phiên bản Q8_0 (gần như hoàn hảo) với full GPU acceleration, bởi vì 10.45 GB vẫn nằm gọn dưới mức giới hạn 12 GB của bạn!
Luôn săn badge tên lửa xanh. Nếu model không hiện biểu tượng này, hãy chọn quantization nhỏ hơn hoặc model nhỏ hơn.
Sơ Đồ Ra Quyết Định 🔄
Cách chọn model hoàn hảo trong 2 phút:
| |
Model Đề Xuất Theo Phần Cứng 🎯
💚 Tiết Kiệm (6–8 GB VRAM) — RTX 3060 8GB, RTX 4060
| Model | Quant | Kích Thước | Tốt Cho |
|---|---|---|---|
| Qwen2.5-7B-Instruct | Q4_K_M | ~4.5 GB | Chat chung |
| Llama-3.1-8B-Instruct | Q4_K_M | ~5 GB | Đa năng |
| Phi-4-Mini-3.8B | Q6_K | ~3 GB | Phản hồi nhanh |
| DeepSeek-Coder-6.7B | Q4_K_M | ~4 GB | Lập trình |
💛 Tầm Trung (12 GB VRAM) — RTX 3060 12GB, RTX 4070
| Model | Quant | Kích Thước | Tốt Cho |
|---|---|---|---|
| Qwen3.5-9B | Q4_K_M | ~6.5 GB | 🏆 Đa năng tốt nhất |
| Qwen2.5-14B-Instruct | Q4_K_M | ~9 GB | Chat thông minh hơn |
| Qwen2.5-Coder-14B | Q4_K_M | ~9 GB | Code tốt nhất |
| DeepSeek-R1-Distill-14B | Q4_K_M | ~9 GB | Toán & suy luận |
| Llama-3.1-8B-Instruct | Q6_K | ~6.5 GB | Chất lượng cao, đa năng |
💜 Cao Cấp (16–24 GB VRAM) — RTX 4080, RTX 4090, RTX 3090
| Model | Quant | Kích Thước | Tốt Cho |
|---|---|---|---|
| Qwen2.5-32B-Instruct | Q4_K_M | ~20 GB | Gần bằng cloud |
| DeepSeek-R1-Distill-32B | Q4_K_M | ~20 GB | Suy luận tốt nhất |
| Llama-3.1-70B | Q2_K | ~24 GB | Trí tuệ tối đa (chỉ GPU 24GB) |
| Qwen2.5-Coder-32B | Q4_K_M | ~20 GB | Code local tốt nhất |
Cài Đặt LM Studio Quan Trọng ⚙️
Sau khi tải model, các cài đặt này sẽ quyết định trải nghiệm:
GPU Offload
Đặt thành max (tất cả layers). Đảm bảo toàn bộ model chạy trên GPU thay vì rơi về CPU.
Context Length (Độ Dài Ngữ Cảnh)
Đây là lượng text model có thể “nhớ” trong một cuộc hội thoại.
| Context Length | Chi Phí VRAM | Trường Hợp Dùng |
|---|---|---|
| 2048 | Thấp | Hỏi đáp ngắn |
| 4096 | Trung bình | Hội thoại bình thường |
| 8192 | Cao hơn | Tài liệu dài, code |
| 16384+ | Rất cao | Chỉ khi thừa VRAM |
Mẹo: Bắt đầu với 4096. Nếu bị lỗi out-of-memory, giảm xuống 2048. Nếu còn dư VRAM, tăng lên 8192.
Temperature (Nhiệt Độ)
Kiểm soát mức độ “sáng tạo” của model:
| Temperature | Hành Vi |
|---|---|
| 0.0 – 0.3 | Rất tập trung, xác định — tốt cho code & hỏi đáp kiến thức |
| 0.4 – 0.7 | Cân bằng — tốt cho chat chung |
| 0.8 – 1.0 | Sáng tạo, đa dạng — tốt cho viết lách & brainstorm |
Cách Benchmark Model 📊
Sau khi load model, bạn muốn kiểm tra xem nó chạy tốt không. Đây là những gì cần kiểm tra:
Tokens Per Second (tok/s)
LM Studio hiển thị con số này ở thanh dưới khi đang sinh text:
| Tốc Độ | Đánh Giá | Ý Nghĩa |
|---|---|---|
| 30+ tok/s | 🏆 Tuyệt vời | Gần như tức thì — GPU chạy hoàn hảo |
| 15–30 tok/s | ✅ Tốt | Thoải mái chat real-time |
| 5–15 tok/s | ⚠️ Chấp nhận được | Dùng được nhưng có độ trễ |
| <5 tok/s | ❌ Quá chậm | Model có thể đang tràn sang CPU — thử quant nhỏ hơn |
Prompt Benchmark Nhanh
Thử prompt này để test cả tốc độ lẫn chất lượng:
| |
Nếu phản hồi nhanh, chính xác, và trình bày đẹp — bạn đã tìm được model của mình. 🎉
Sai Lầm Phổ Biến Cần Tránh ❌
Tải model to nhất — Model 70B ở Q2 tệ hơn 14B ở Q6. Chất lượng quan trọng hơn kích thước khi nén quá mạnh.
Bỏ qua badge xanh — Nếu LM Studio báo “Partial GPU Offload”, trải nghiệm sẽ tệ. Luôn nhắm “Full GPU Offload Possible”.
Đặt context quá cao — Context length ăn VRAM. Context 32K trên GPU 12GB với model 9B sẽ crash.
Không test nhiều model — Model khác nhau giỏi task khác nhau. Model “tốt nhất” phụ thuộc vào TRƯỜNG HỢP SỬ DỤNG của bạn.
Quên cập nhật — Các tác giả model thường xuyên release quantization và bản sửa lỗi mới. Hãy kiểm tra cập nhật.
Tóm Tắt Nhanh 📋
Cho ai chỉ muốn câu trả lời:
| |
Giờ thì lên đường chạy AI trên phần cứng của mình — không subscription, không giới hạn, không phụ thuộc cloud. Chỉ có bạn và GPU, tạo nên điều kỳ diệu. 🚀