
Tôi từng nói chuyện với một đồng nghiệp có thể đọc vanh vách “1 byte = 8 bit” ngay cả khi đang mơ ngủ, nhưng lại đứng hình khi bị hỏi: “Tên của mày tốn bao nhiêu byte?”
Giờ thì ta xử lý câu hỏi đó.
Mô hình Bãi Đỗ Xe
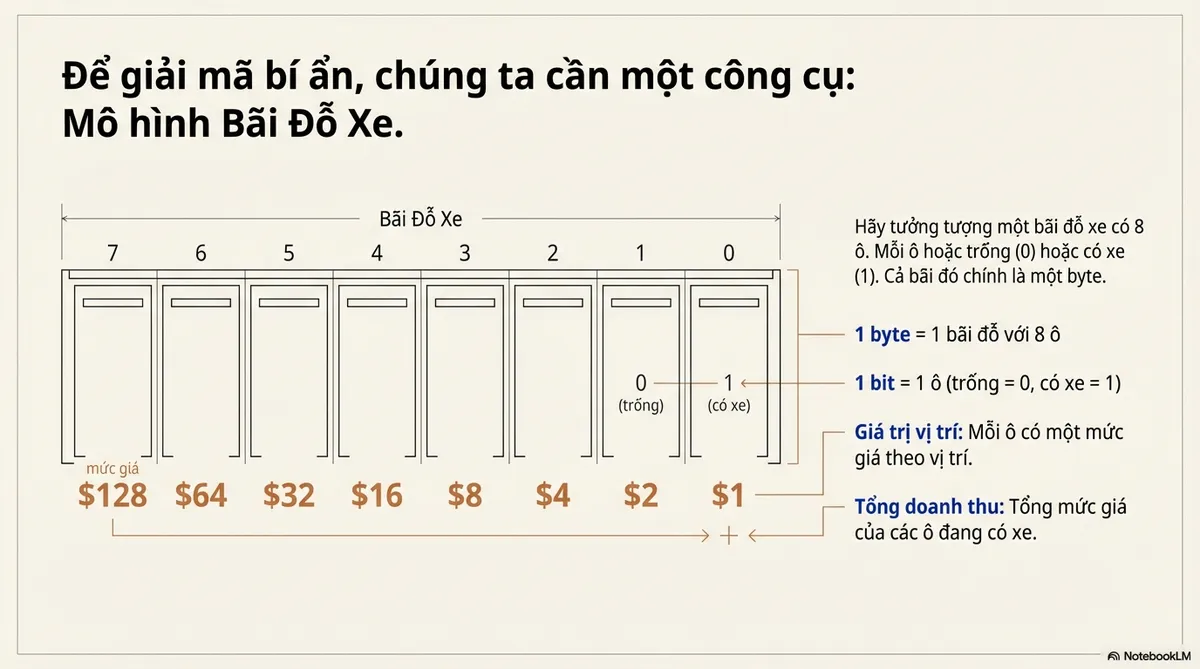
Hãy tưởng tượng một bãi đỗ xe có 8 ô. Mỗi ô hoặc trống (0) hoặc có xe (1). Cả bãi đó chính là một byte.
| Ô # | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| Giá | $128 | $64 | $32 | $16 | $8 | $4 | $2 | $1 |
- 1 byte = 1 bãi đỗ với 8 ô
- 1 bit = 1 ô (trống = 0, có xe = 1)
- Mỗi ô có một mức giá theo vị trí: ô 0 giá $1, ô 1 giá $2, ô 7 giá $128
- Tổng doanh thu = tổng mức giá của các ô đang có xe
Đây là trực quan hóa cấu trúc của một byte:
00000001 → chỉ ô cuối có xe → doanh thu = 1
00000010 → ô kế bên có xe → doanh thu = 2
11111111 → cả 8 ô đều đầy → doanh thu = 128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 = 255
Con số (0–255) chỉ phụ thuộc vào việc ô nào có xe.
ASCII
Vì sao máy tính lại nhóm 8 bit (2³) thành 1 byte? Sao không phải 6 hay 10?
Câu trả lời ngắn: 8 bit là kích thước “vừa đẹp” cho văn bản. 🐧

ASCII Character Set
Để lưu văn bản, máy tính cần ánh xạ ký tự → số. Với 8 bit, bạn có 256 giá trị (0–255). Chừng đó đủ chứa mọi chữ cái tiếng Anh (a-z, A-Z), chữ số và ký hiệu, còn dư chỗ.
Hãy nghĩ 256 giá trị này như 256 cấu hình bãi đỗ xe khác nhau. Mỗi cấu hình tương ứng với một ký tự.
Nhưng có một cú twist: ASCII chuẩn thực ra chỉ cần 7 bit (128 giá trị).
Vậy sao lại 8? Thực tế là một hỗn hợp của lựa chọn phần cứng “hên xui” thời kỳ đầu và nhu cầu có một “đơn vị” chuẩn hóa để chứa nhiều thứ hơn là chỉ văn bản đơn giản.
Đây là trực quan hóa cách ký tự được phân bố trong byte:
ASCII Encoding
Vậy làm sao chuyển qua lại giữa ký tự và byte như hình minh họa ở trên?
Lấy ví dụ mã hóa chữ “Y” (trong YELL).
Bước 1: Character set Ký tự → Số
Tra bảng ASCII: Y = 89
Bước 2: Encoding Số → Nhị phân
Đây là chỗ nhiều người kẹt. Hãy dùng phương pháp thử-bit (bit-test). Thuộc lòng dãy: 128, 64, 32, 16, 8, 4, 2, 1
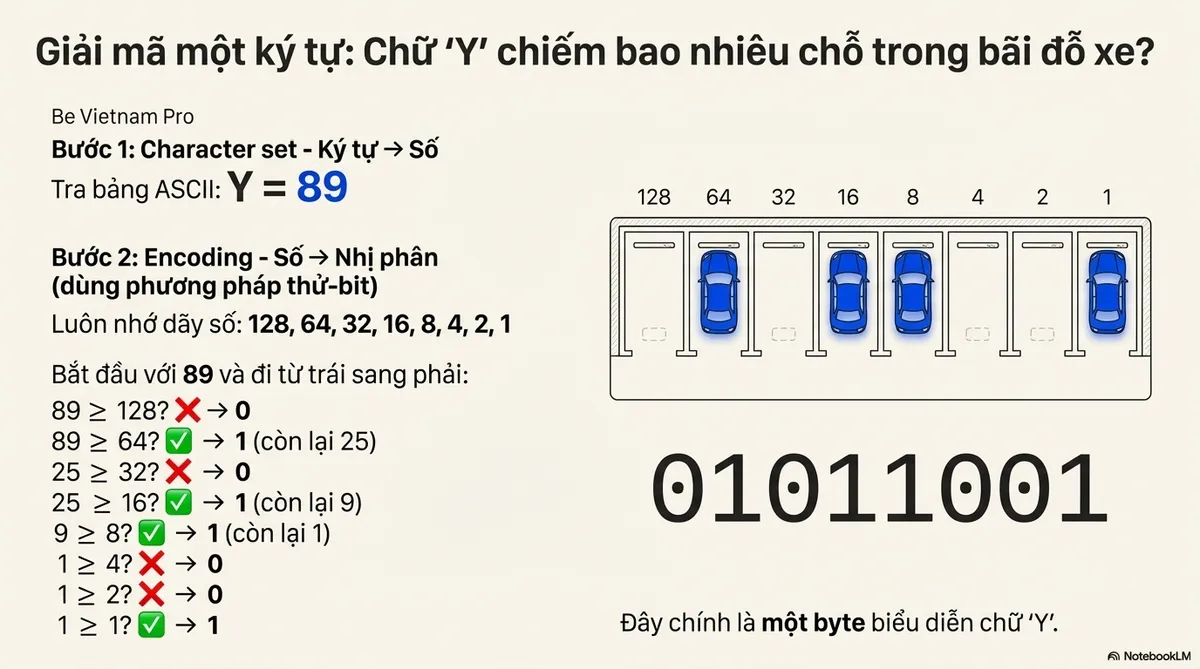
Bắt đầu với 89 và đi từ trái sang phải:
- 89 ≥ 128? ❌ → 0
- 89 ≥ 64? ✅ → 1 (89 − 64 = 25)
- 25 ≥ 32? ❌ → 0
- 25 ≥ 16? ✅ → 1 (25 − 16 = 9)
- 9 ≥ 8? ✅ → 1 (9 − 8 = 1)
- 1 ≥ 4? ❌ → 0
- 1 ≥ 2? ❌ → 0
- 1 ≥ 1? ✅ → 1
| |
Kết quả: 01011001. Đó là một byte.
Cũng có cách “chia 2 liên tục” để đổi thập phân sang nhị phân, nhưng cá nhân tôi thấy hơi mệt và hiếm khi dùng.
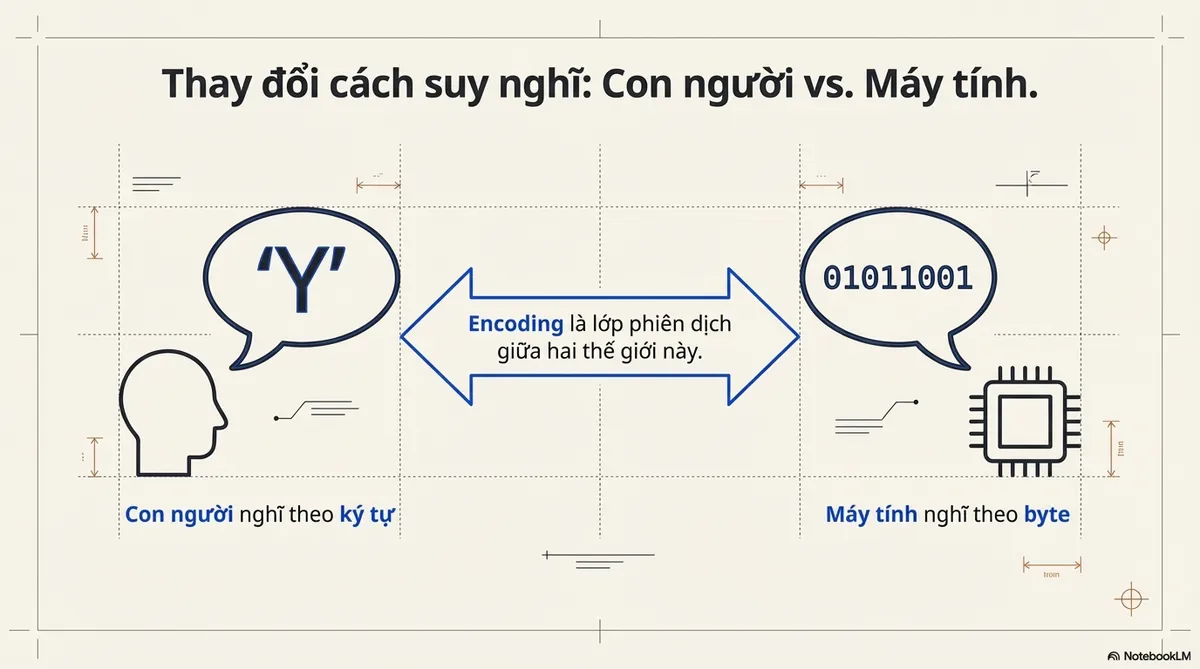
Chuyển đổi tư duy:
- Con người nghĩ theo ký tự
- Máy tính nghĩ theo byte
- Encoding là lớp phiên dịch giữa hai thế giới
Lớn Hơn ASCII
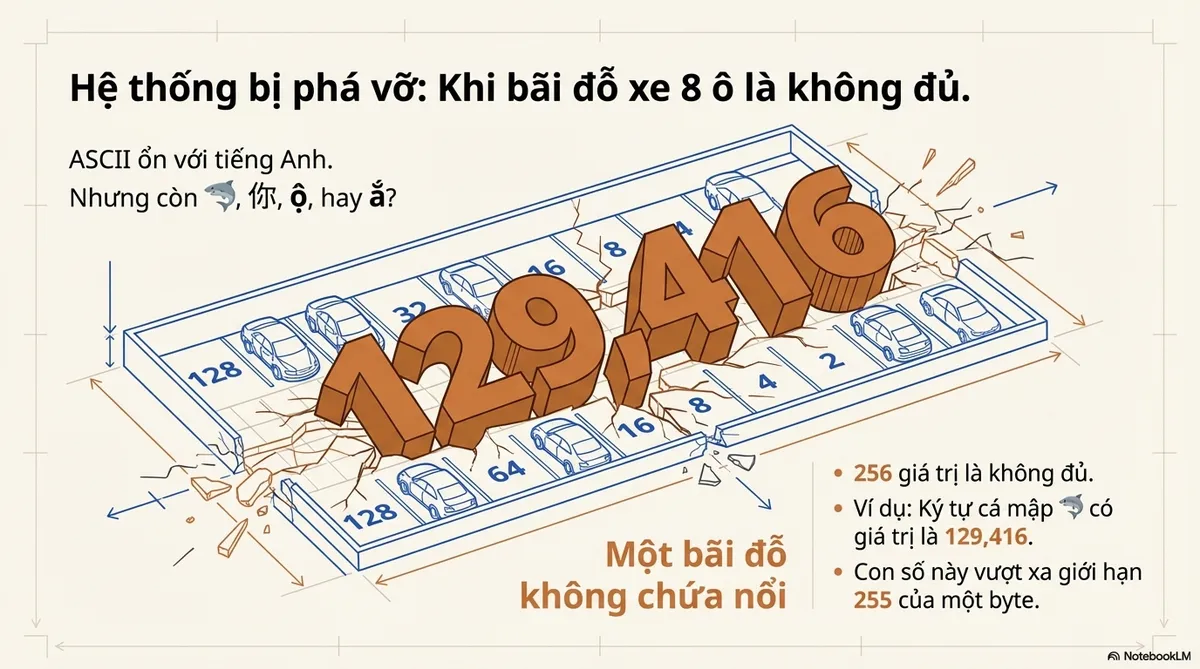
ASCII ổn với tiếng Anh. Nhưng còn 🦈, 你, ộ, hay ắ?
256 giá trị là không đủ. Ta cần một thứ “to hơn”.



Bộ ký tự Unicode
Hỏi: Unicode có giống ASCII nhưng “bự hơn” không?
Đáp: Cũng gần đúng, nhưng chưa đủ chính xác.
ASCII có 2 phần:
- Bộ ký tự (character set): đổi ký tự → số thập phân
- Encoding: đổi số thập phân → nhị phân
Unicode chỉ là một bộ ký tự (character set). Nó gán một số duy nhất (code point) cho mỗi ký tự, nhưng không bắt bạn phải lưu số đó dưới dạng bit như thế nào.
| Ký tự | Code Point | Thập phân |
|---|---|---|
| 🦈 | U+1F988 | 129,416 |
| 你 | U+4F60 | 20,320 |
| ộ | U+1EC7 | 7,879 |
| ắ | U+1EA5 | 7,845 |
Unicode 17.0 có hơn 150.000 code point.
Phần “encoding” (lưu bằng byte ra sao)? Đó là lúc UTF-8 xuất hiện.
UTF-8 Encoding
Code point → byte. Làm thế nào?
Với ASCII, chuyện rất đơn giản: một ký tự = một byte.
Nhưng 🦈 là 129,416 (vượt xa 255). Một bãi đỗ (một byte) không chứa nổi.
Vậy làm sao phân bố “xe” qua nhiều bãi đỗ để biểu diễn số lớn?
Ta cần nhiều bãi đỗ hơn.
UTF-8: Hệ thống xâu chuỗi nhiều bãi
Xâu chuỗi nhiều bãi tạo ra một vấn đề: máy tính biết đâu là điểm kết thúc của một ký tự và bắt đầu của ký tự kế tiếp?
UTF-8 giải quyết bằng khuôn byte (byte templates). Vài bit đầu cho biết bạn cần đọc bao nhiêu byte.
| Số byte | Khuôn |
|---|---|
| 1 | 0xxxxxxx |
| 2 | 110xxxxx 10xxxxxx |
| 3 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Các tiền tố (110, 1110, 11110) nói với máy tính: “Tôi là ký tự nhiều byte, hãy đọc thêm X byte nữa.”
Ví dụ: mã hóa 🦈
- Tìm code point: 🦈 = U+1F988 = 129,416
- Kiểm tra khoảng: 129,416 nằm trong 65,536 – 1,114,111 → cần 4 byte
- Đổi sang nhị phân: biểu diễn code point ở dạng nhị phân (21 bit)
- Nhét vào khuôn: phân phối các bit đó vào khuôn 4 byte
Áp dụng với Python
Trong Python, text (str) và raw bytes (bytes) là hai kiểu khác nhau.
strlà Unicode text (chuỗi các code point)encode("utf-8")biến text đó thành đúng các byte sẽ được lưu/truyền đi
| |
Bạn đang thấy gì ở đây:
b'...'nghĩa là: đây là bytes, không phải text- Mỗi
\x..là một byte viết ở dạng hex (f0,9f,a6,88) - Cùng các byte đó ở dạng thập phân là
240, 159, 166, 136 - Nó tốn 4 byte vì 🦈 nằm ngoài ASCII, nên UTF-8 dùng khuôn 4 byte
Và bạn luôn có thể decode ngược lại thành text:
| |
UTF-8 BOM
BOM (Byte Order Mark) là một chuỗi byte tùy chọn đặt ở đầu file để báo encoding (và với UTF‑16/UTF‑32 còn để chỉ thứ tự byte).
UTF-8 không cần BOM. Nhưng đôi khi một số tool/editor vẫn lưu file theo kiểu “UTF‑8 with BOM”, tức là nó chèn thêm 3 byte ở ngay đầu file:
- BOM (hex):
EF BB BF - Nếu decode ra text, nó tương ứng với ký tự Unicode
U+FEFF
Phần lớn trường hợp thì vô hại. Nhưng nó hay gây lỗi khi parser “khó tính” mong byte đầu tiên phải là một ký tự cụ thể (ví dụ JSON phải bắt đầu bằng {), trong khi file lại bắt đầu bằng BOM.
Kiểm tra/xử lý nhanh:
| |
| |
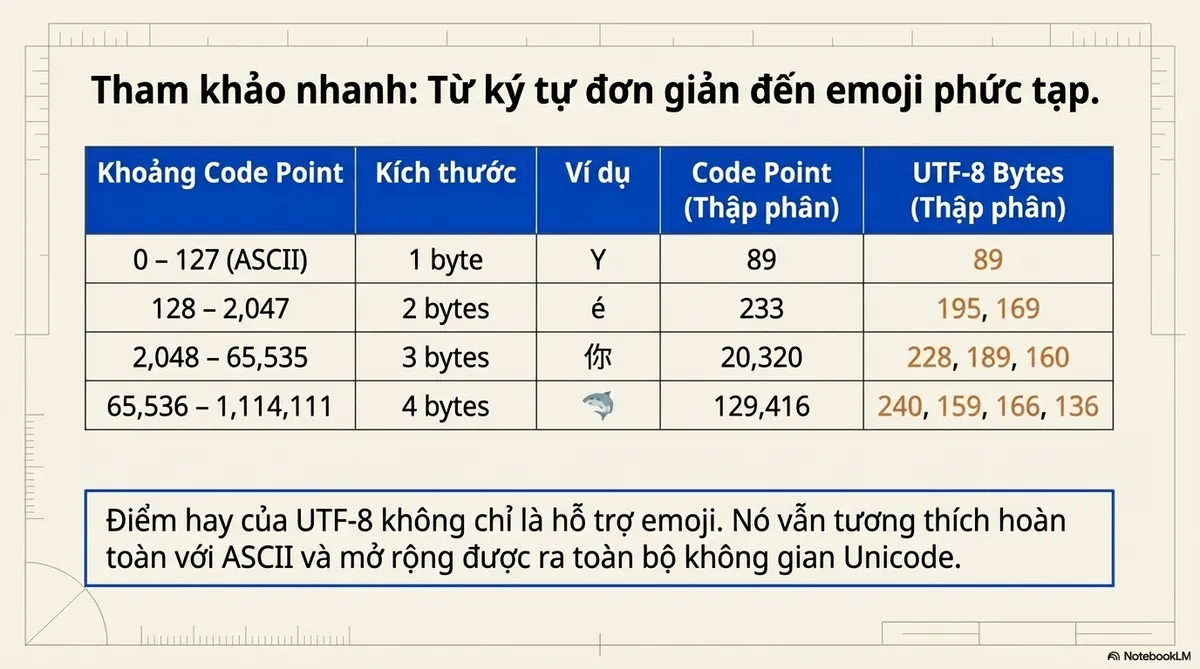
Tham khảo nhanh
| Khoảng code point | Kích thước | Ví dụ | Code Point | Thập phân | UTF-8 bytes (thập phân) |
|---|---|---|---|---|---|
| 0 – 127 (ASCII) | 1 byte | Y | U+0059 | 89 | 89 |
| 128 – 2,047 | 2 byte | é | U+00E9 | 233 | 195, 169 |
| 2,048 – 65,535 | 3 byte | 你 | U+4F60 | 20,320 | 228, 189, 160 |
| 65,536 – 1,114,111 | 4 byte | 🦈 | U+1F988 | 129,416 | 240, 159, 166, 136 |
Kết luận: cái hay của UTF-8 không chỉ là hỗ trợ emoji. Nó vẫn tương thích ASCII và mở rộng được ra toàn bộ không gian Unicode.

Máy tính lượng tử (Bonus)

Giờ ta phá luật vật lý của bãi đỗ xe một chút.
Một bit cổ điển thì rất đơn giản: ô hoặc trống (0) hoặc có xe (1).
Một quantum bit (qubit) thì… lạ. Chiếc xe bước vào trạng thái chồng chập (superposition).
- Chồng chập (superposition): chiếc xe ở trạng thái “ma”, vừa như có xe vừa như không cùng lúc.
- Đo (measurement): khi bạn nhìn/đo, chiếc xe bị ép phải “chọn phe”. Nó lập tức sụp về 0 hoặc 1 bình thường.
Nó giống “Ô đỗ xe của Schrödinger”. Rùng rợn? Có. Nhưng nhờ đó, máy tính lượng tử có thể tính toán rất nhiều khả năng song song.
Với tình trạng “lúc vui lúc buồn” đó, qubit dùng cho việc khác, không phải để lưu trữ như cách cổ điển.
